scanner类
- scanner本质上就是一个扫描器,可以看作一个指针不断的移动扫描,对扫描的内容进行分流判断。为将模板转换为tokens提供了方法支持。
export default class Scanner{
constructor(string) {
this.string = string;
this.pos = 0;
this.tail = string;
}
eos() {
return this.tail === ''? false : true;
}
scan(reg) {
let rel = this.tail.match(reg);
if (!rel) {
return '';
}
this.tail = this.tail.substring(rel[0].length);
this.pos += rel[0].length;
return rel[0];
}
scanUntil(reg) {
let rel = this.tail.match(reg), qz;
if (!rel) {
qz = this.tail;
this.tail = '';
} else if (rel.index === 0) {
qz = '';
} else {
qz = this.tail.substring(0, rel.index);
this.tail = this.tail.substring(rel.index);
}
this.pos += qz.length;
return qz;
}
}
- eos方法:判断模板字符串是否扫描完。
- scanUtil方法:主要用来截取循环字段、变量字段以及普通文本。
- scan方法:主要用来扫描并跳过'{{'。
parseTemplate函数
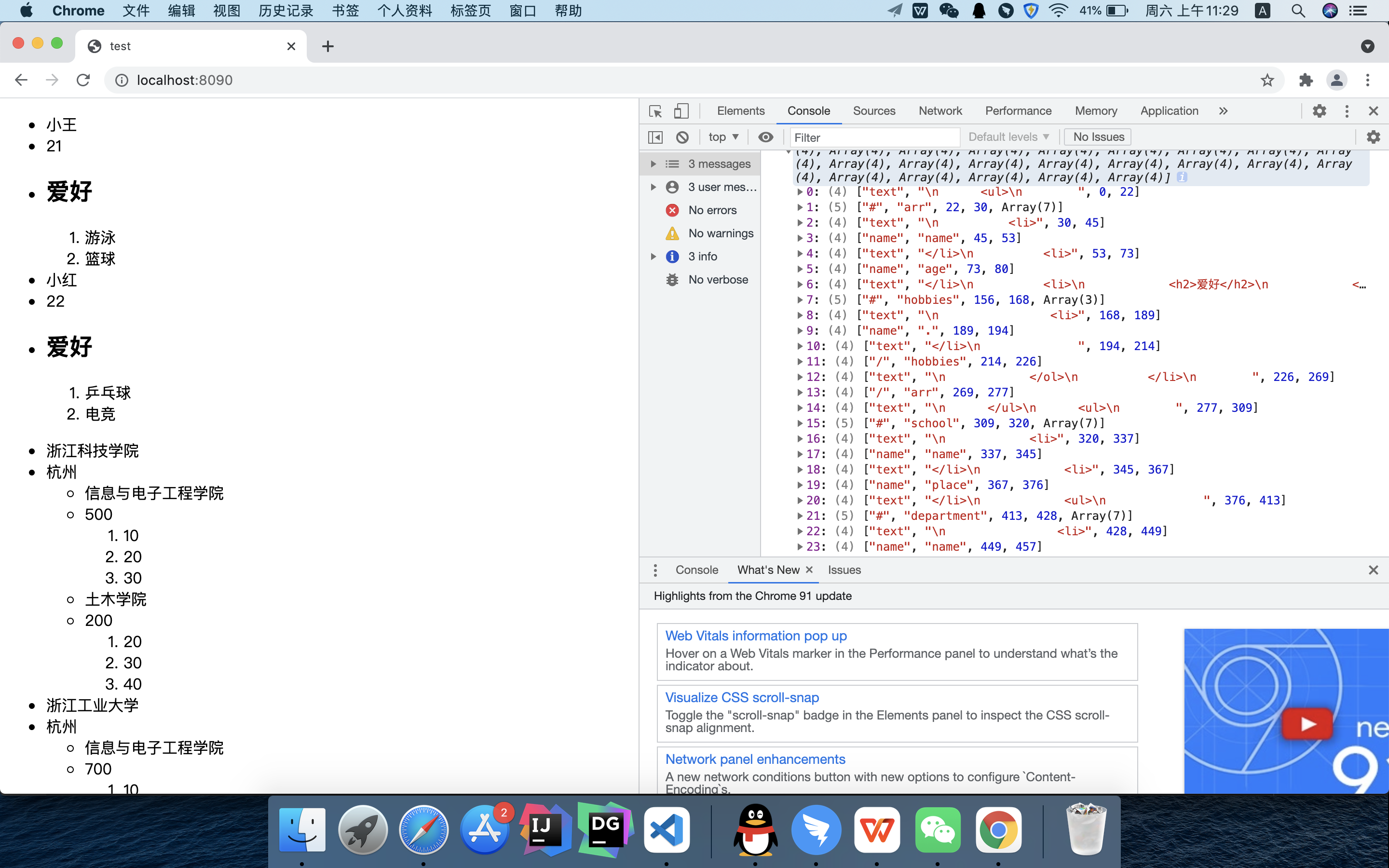
- parseTemplate函数主要就是基于scanner扫描类进行扫描,生成扁平化tokens。
import nestTokens from './nestTokens';
import Scanner from './scanner';
export default function parseTemplate(template) {
let scanner = new Scanner(template);
let tokens = [], ed = 0;
const reg = /\{\{|\}\}/;
while (scanner.eos()) {
let rel1 = scanner.scanUntil(reg);
let rel2 = scanner.scan(reg);
if (rel2 === '}}') {
if (rel1[0] === '#') {
tokens.push([
'#',
rel1.slice(1),
ed,
scanner.pos + 2
]);
} else {
tokens.push([
rel1[0] === '/' ? '/' : 'name',
rel1[0] === '/' ? rel1.slice(1) : rel1,
ed,
scanner.pos + 2
]);
}
ed = scanner.pos + 2;
} else {
tokens.push([
'text',
rel1,
ed,
scanner.pos
]);
ed = scanner.pos;
}
}
let rel = nestTokens(tokens, 0);
tokens.forEach(x => {
delete x.flag;
});
return rel;
}
nestTokens函数
- nestTokens函数主要将扁平化的tokens打成嵌套的tokens
以下个人使用递归方式实现
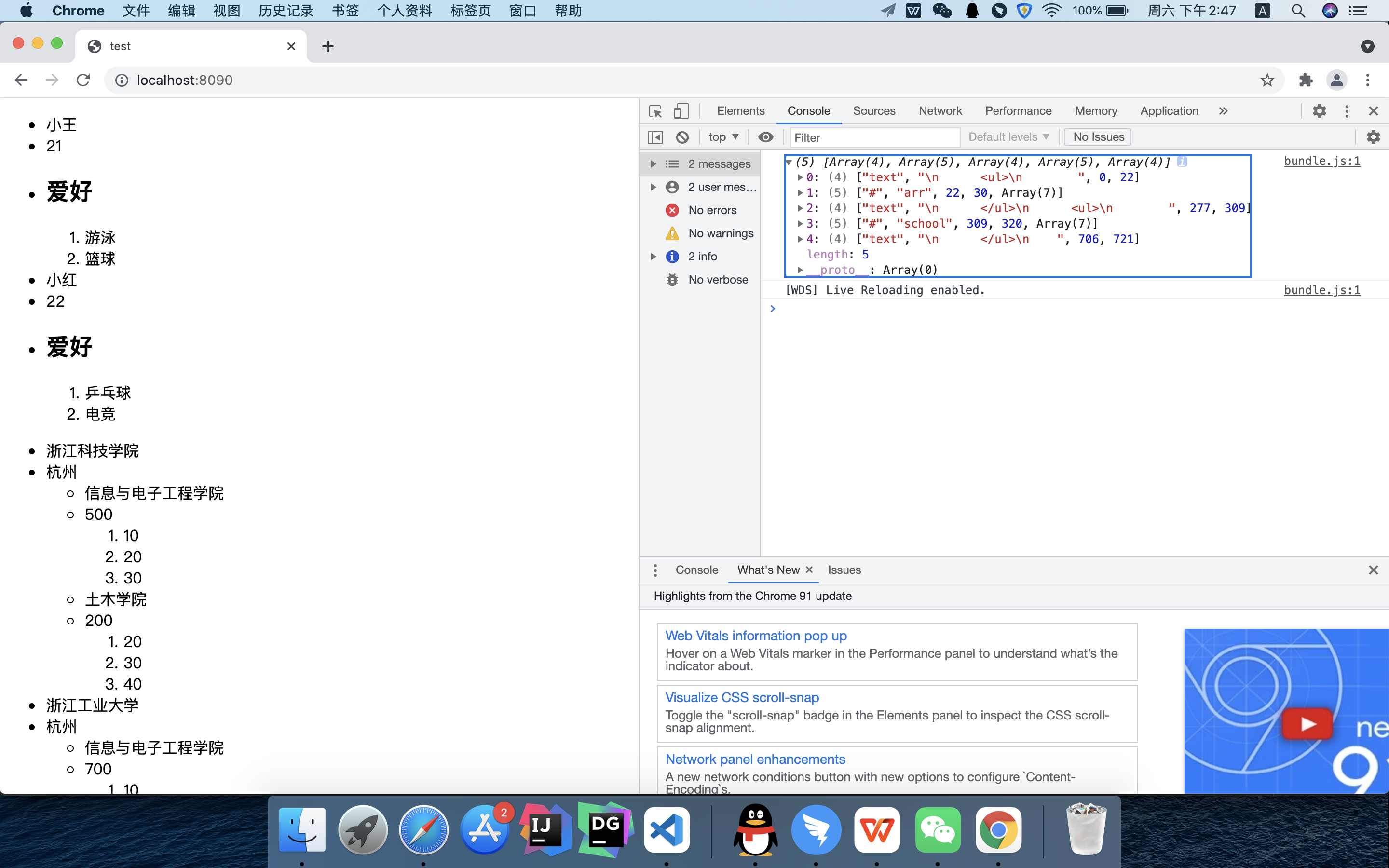
export default function nestTokens(tokens, pos) {
let rel = [];
for (let i = pos; i < tokens.length; i++){
let token = tokens[i];
if (token.flag) continue;
token.flag = true;
if (token[0] === '#') {
let son = nestTokens(tokens, i + 1);
token.push(son);
rel.push(token);
} else if (token[0] === '/') {
return rel;
} else {
rel.push(token);
}
}
return rel;
}
mustache源码中使用收集器指针实现
function nestTokens(tokens) {
/**
* nestedTokens:结果数组
* collector:收集器(核心)
* sections:栈
*/
var nestedTokens = [];
var collector = nestedTokens;
var sections = [];
var token, section;
for (var i = 0, numTokens = tokens.length; i < numTokens; ++i) {
token = tokens[i];
switch (token[0]) {
/**
* 遇到#类型和^类型的token
* 1.往sections栈和收集器所指向的当前数组里压入token
* 2.然后在目前的尾部新建一个空数组,用来存放循环体内的token
*/
case '#':
case '^':
collector.push(token);
sections.push(token);
collector = token[4] = [];
break;
/**
* 遇到/类型的token
* 1.此时需要将sections栈顶的#类型token弹出
* 2.弹出的过程中,将#token的尾部增加结束位置,来表明这个循环指令所对应的在模板字符串的范围
* 3.如果此时sections栈有token,那么collector收集器直接跳到上一个循环即外层#token
*/
case '/':
section = sections.pop();
section[5] = token[2];
collector = sections.length > 0 ? sections[sections.length - 1][4] : nestedTokens;
break;
/**
* 遇到普通类型的token,即不带#和/的token
* 直接压入收集器所指向的当前数组
*/
default:
collector.push(token);
}
}
return nestedTokens;
}
lookup函数
- lookup函数主要去提供的真实数据里去找对应key变量
export default function lookup(data, keyName) {
const index = keyName.search(/\./);
if (index !== -1 && keyName.length === 1) {
return data;
} else {
if (index === -1) {
return data[keyName];
} else {
let str = keyName.slice(0, index);
return lookup(data[str], keyName.slice(index + 1));
}
}
}
renderTemplate函数
- renderTemplate函数主要结合tokens和真实数据,通过拼接字符串的形式去构建一个真实的dom字符串
import lookup from './lookup';
export default function renderTemplate(tokens, data) {
let resultStr = '';
for (let i = 0, len = tokens.length; i < len; i++){
let token = tokens[i];
if (token[0] === 'text') {
resultStr += token[1];
} else if (token[0] === 'name') {
resultStr += lookup(data, token[1]);
} else {
const dt = data[token[1]];
if (dt.length) {
for (let i = 0; i < dt.length; i++){
resultStr += renderTemplate(token[4], dt[i]);
}
} else {
resultStr += renderTemplate(token[4], dt);
}
}
}
return resultStr;
}
github地址
自我实现的mustache模板引擎